Overview
What is Kubeflow Training Operator ?
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, TensorFlow, XGBoost, and others.
User can integrate other ML libraries such as HuggingFace, DeepSpeed, or Megatron with Training Operator to orchestrate their ML training on Kubernetes.
Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK.
Training Operator implements centralized Kubernetes controller to orchestrate distributed training jobs.
Users can run High-performance computing (HPC) tasks with Training Operator and MPIJob since it supports running Message Passing Interface (MPI) on Kubernetes which is heavily used for HPC. Training Operator implements V1 API version of MPI Operator. For MPI Operator V2 version, please follow this guide to install MPI Operator V2.
Custom Resources for ML Frameworks
To perform distributed training Training Operator implements the following Custom Resources for each ML framework:
| ML Framework | Custom Resource |
|---|---|
| PyTorch | PyTorchJob |
| TensorFlow | TFJob |
| XGBoost | XGBoostJob |
| MPI | MPIJob |
| PaddlePaddle | PaddleJob |
Architecture
This diagram shows the major features of Training Operator and supported ML frameworks.
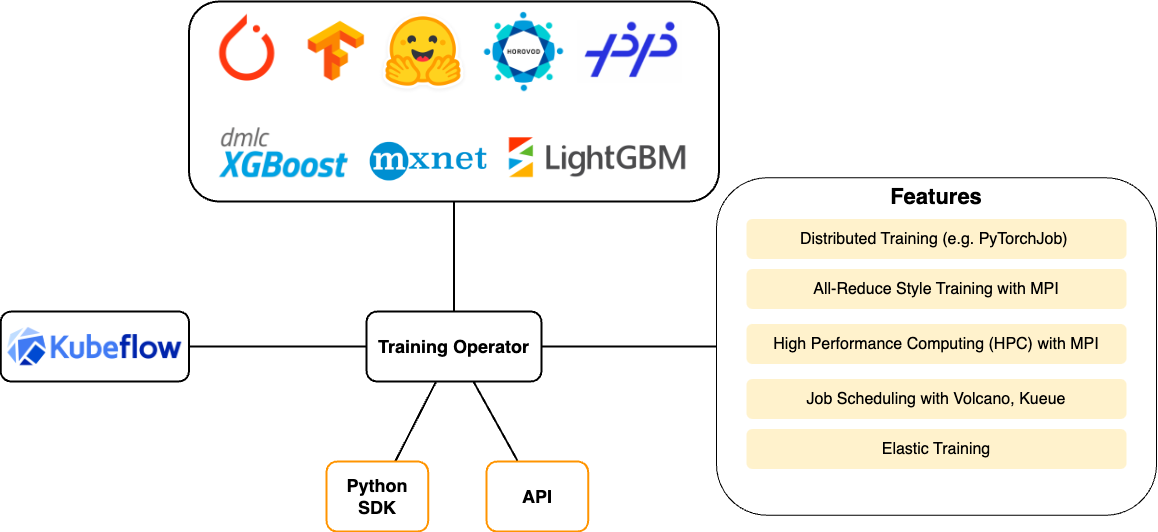
Training Operator is responsible for scheduling the appropriate Kubernetes workloads to implement various distributed training strategies for different ML frameworks. The following examples show how Training Operator allows to run distributed PyTorch and TensorFlow on Kubernetes.
Distributed Training for PyTorch
This diagram shows how Training Operator creates PyTorch workers for ring all-reduce algorithm.

User is responsible for writing a training code using native
PyTorch Distributed APIs
and create a PyTorchJob with required number of workers and GPUs using Training Operator Python SDK.
Then, Training Operator creates Kubernetes pods with appropriate environment variables for the
torchrun CLI to start distributed
PyTorch training job.
At the end of the ring all-reduce algorithm gradients are synchronized
in every worker (g1, g2, g3, g4) and model is trained.
You can define various distributed strategies supported by PyTorch in your training code
(e.g. PyTorch FSDP), and Training Operator will set
the appropriate environment variables for torchrun.
Distributed Training for TensorFlow
This diagram shows how Training Operator creates TensorFlow parameter server (PS) and workers for PS distributed training.

User is responsible for writing a training code using native
TensorFlow Distributed APIs and create a
TFJob with required number PSs, workers, and GPUs using Training Operator Python SDK.
Then, Training Operator creates Kubernetes pods with appropriate environment variables for
TF_CONFIG
to start distributed TensorFlow training job.
Parameter server splits training data for every worker and averages model weights based on gradients produced by every worker.
You can define various distributed strategies supported by TensorFlow
in your training code, and Training Operator will set the appropriate environment
variables for TF_CONFIG.
Getting Started
You can create your first Training Operator job using Python SDK. Define the training function that implements end-to-end model training. Training Operator schedules appropriate resources to run this training function on every Worker.
Install Training Operator SDK:
pip install kubeflow-training
You can implement your training loop in the train function. Each Worker will execute this function on the appropriate Kubernetes Pod. Usually, this function contains logic to download dataset, create model, and train the model.
World Size and Rank will be set automatically in env variables by Training Operator controller to perform PyTorch DDP.
For example:
def train_func():
import torch
import os
# Create model.
class Net(torch.nn.Module):
"""Create the Pytorch model"""
...
model = Net()
# Download dataset.
train_loader = torch.utils.data.DataLoader(...)
# Attach model to PyTorch distributor.
torch.distributed.init_process_group(backend="nccl")
Distributor = torch.nn.parallel.DistributedDataParallel
model = Distributor(model)
# Start model training.
model.train()
# Start PyTorchJob with 100 Workers and 2 GPUs per Worker.
from kubeflow.training import TrainingClient
TrainingClient().create_job(
name="pytorch-ddp",
func=train_func,
num_workers=100,
resources_per_worker={"gpu": "2"},
)
Next steps
Learn more about the PyTorchJob APIs.
Follow the scheduling guide to configure various job schedulers for Training Operator jobs.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.